我们已预见光线追踪和 GPU 渲染的未来。在这篇文章中,Vlado 先生对 GeForce RTX 显示适配器的基准实验,探究其效能与意义。
概述
这是我们前一篇 RTX 光线追踪文章的续集。当我们撰写我们该文章时,GeForce RTX 卡才刚刚公布,但我们无法分享任何特定的基准检验结果,因为当时显示适配器尚未正式发布。
现在这些显示适配器已经发布,我们可以分享实验结果了。这里我们只展示 GeForce RTX 2080 和 GeForce RTX 2080 Ti 卡以及上一代 GeForce GTX 1080 Ti 的结果,因为这些显示适配器属于顶级产品线。
所有最新版本的 V-Ray GPU 都已经在新卡上运行而没有任何问题,尽管他们尚未利用新的 RT Cores;我们正在开发这方面的功能,您可以在下面读到我们的实验结果。
我们使用以下场景(有一些是修改过的 Evermotion 场景)来进行基准检验:

ArchInteriors 13, scene 8

白色的房间(White room)

ArchInteriors 13, scene 11

ArchExteriors 25, scene 2

ArchInteriors 33, scene 8

拉维纳之湖(Lake Lavina)
CUDA 性能表现
对于第一组测试,我们使用了常规 CUDA 版本的 V-Ray GPU Next,这个版本还没有使用 RT Cores。我们测量了 RTX 2080 和 RTX 2080 Ti 卡的纯 CUDA 性能,并将这两张显示适配器与 GeForce GTX 1080 Ti 进行了比较,后者在 GPU 渲染方面十分受到大众欢迎。
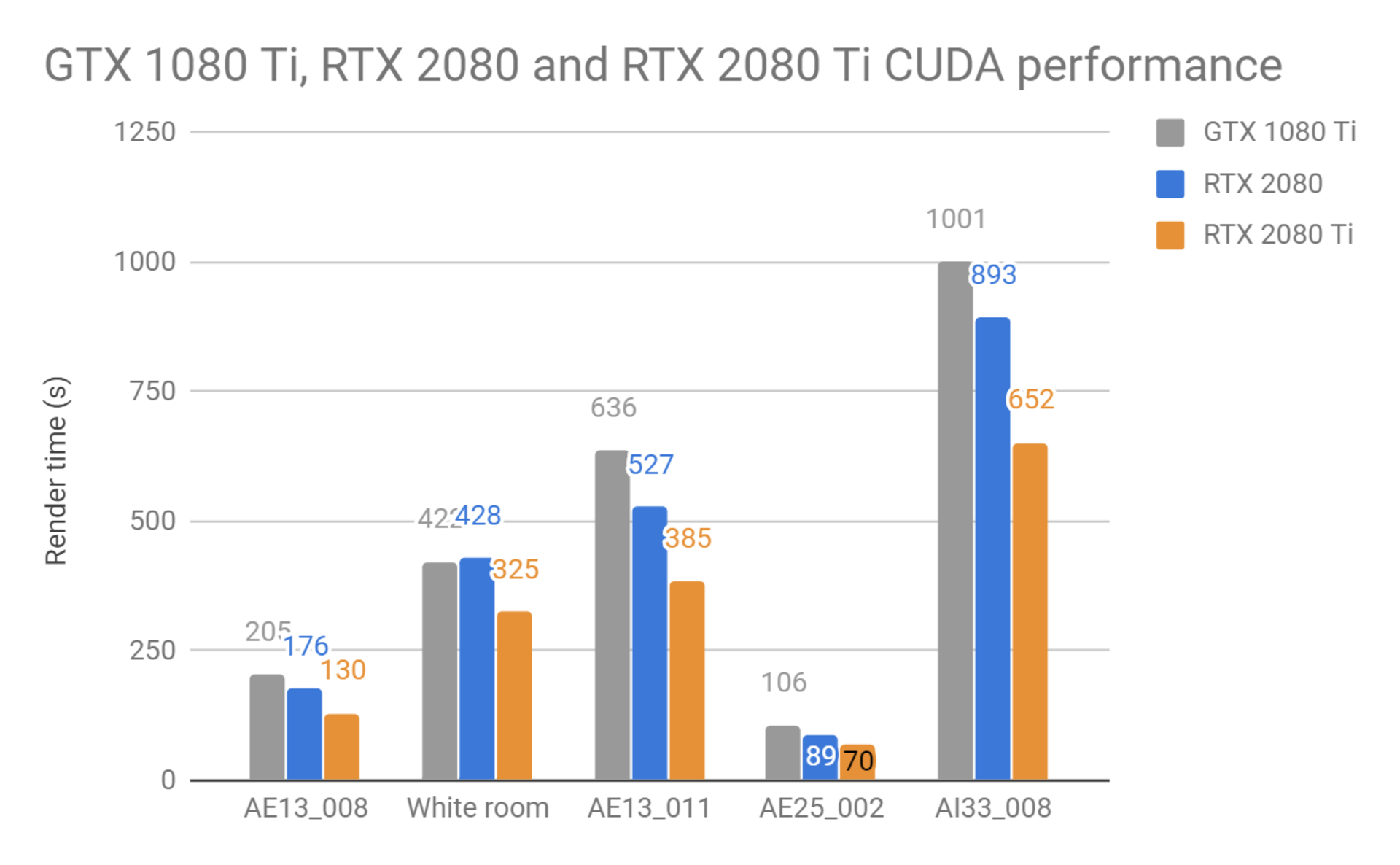
从测试可看出,RTX 2080 和 RTX 2080 Ti 通常比上一代 GTX 1080 Ti 更快。仅比较 Ti 卡时,结果显示,与之前的 Pascal 世代相比,图灵(Turing)世代的显示适配器平均提供 1.52 倍的加速。 这些是以 V-Ray Next 的官方正式版本(shipping versions)进行测试中获得的结果。
RT Core 性能
虽然我们还没有支持 RT Core 的官方版本,但我们已经与 NVIDIA 合作了一段时间,足以为新硬件准备 V-Ray GPU。目前,我们尚未发布的 V-Ray GPU 中的 RT Core 的支持是基于 OptiX 的,但官方正式版尚未提供支持 RT Core 的 OptiX,因此具有 RT Core 支持的 V-Ray GPU 版本仍然需要一段时间。我们仍然可以使用现有的功能进行一些性能测试,请仅记在心,最终软件发表时性能可能会提高。
以下测试使用内置的 V-Ray GPU,并启用了 RT Core 支持。我们期望仍有许多改进可以让我们进一步提高性能。
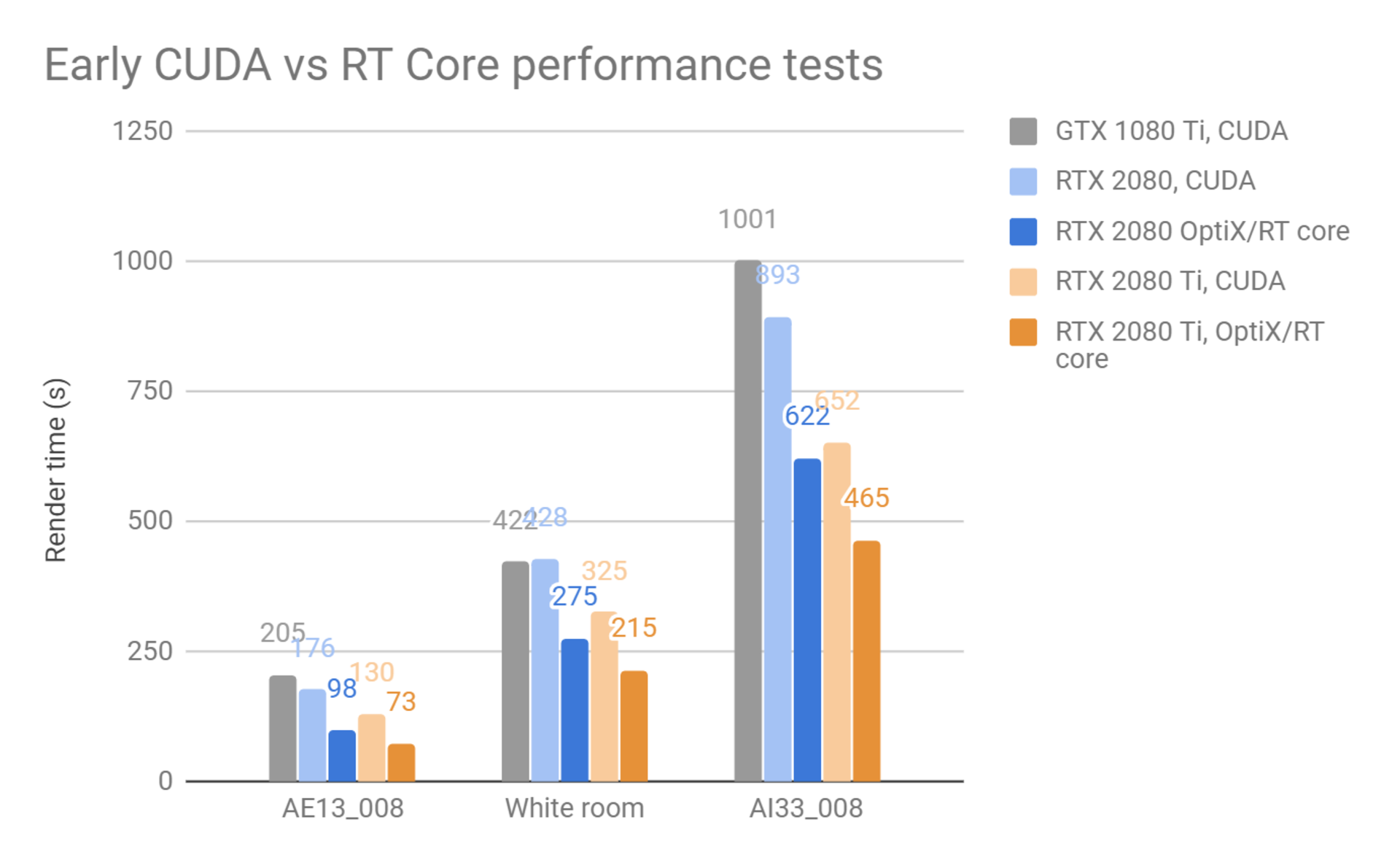
对于这三个测试场景,与纯 CUDA 版本相比,RT Cores 分别提供 1.78x,1.53x 和 1.47x 的加速。 随着我们在未来几个月即将发布官方版本,我们预计这些结果会比现在更好。
DXR 性能
对于这组测试,我们使用了我们首次在 2018 年的 Siggraph 大会上发布 – 拉维纳计划(Project Lavina)的即时光线跟踪引擎。这个引擎是基于 DirectX 12 的 DXR 光线跟踪扩充功能,程序代码是从头开始编写,用于实时射线追踪所需要的性能。该引擎完全基于光线追踪,包括阴影,反射,折射和几次GI反弹,并通过一次的去噪(denoising pass)来平滑渲染结果。过程中完全没有涉及光栅化(rasterization),大量使用 RT 核心。GTX 1080 Ti 等老一代 GPU 不支持 DXR,所以现在我们只能比较两款可用的 GeForce RTX 卡。
出图为 HD 分辨率,DXR 测试的结果以每秒帧数为单位,因此数值越高代表结果越好:

从这些结果来看,RTX 2080 Ti 卡的性能比 RTX 2080 卡平均提高了 1.35倍;这让引擎变得明显地有更佳反应性。
NVLink 性能
除了 RT Cores 之外,新的 RTX 卡还支持 NVLink,这使得 V-Ray GPU 能够在两个 GPU 之间共享内存。这对渲染速度有一些影响 – 在这个基准检验中,我们的目标是测速。为了启用 NVLink,需要使用特殊的 NVLink连接器(也称为 NVLink Bridge)连接这些卡。GeForce RTX 卡有两种类型的连接器:三槽宽和四槽宽,具体取决于显示适配器彼此间的距离。Quadro RTX 卡的 NVLink Bridges 宽度分别为两插槽和三插槽。
适用于 GeForce RTX 卡的三插槽和四插槽 NVLink 连接器:

两个 RTX 2080 Ti 卡与四插槽 NVLink 连接器连接:

要使 NVLink 在 Windows 上运行,GeForce RTX 卡必须从 NVIDIA 控制面板进入 SLI 模式(这项条件不是 Quadro RTX 卡所必需的,在 Linux 上也不需要,并且不建议用于较旧的 GPU)。如果禁用 SLI 模式,NVLink 将不会处于启用状态。这意味着主板必须支持 SLI,否则您将无法将 NVLink 与 GeForce 卡配合使用。另请注意,在 SLI组中,只有连接到主 GPU 的显示器才能运作。此外,如果两个 GeForce GPU 在 SLI 模式下链接,其中至少有一个必须连接显示器(或虚拟插头),以便 Windows 可以识别显示适配器(这项条件不是 Quadro RTX 卡所必需的,也不是 Linux 上必需的)。
启用 SLI 模式的 NVIDIA 控制面板的屏幕截图(Windows 上带有 GeForce RTX 卡的 NVLink 需要 SLI 模式):

RTX 2080 和 RTX 2080 Ti 卡之间的 NVLink 速度也不同,因此我们预期使用 NVLink 会有不同的性能。
在以下测试中,我们使用 SLI 模式和非 SLI 模式的卡片渲染了几个场景,以了解 NVLink 对性能的影响。 我们使用常规 CUDA 版本的 V-Ray GPU 进行这些测试。某些情况下,由于每个 GPU 上的 RAM 限制,场景无法在非 SLI 模式下渲染。
请注意,使用 NVLink,GPU 渲染的可用内存不会恰恰好加倍; 出于性能原因,V-Ray GPU 需要在每个 GPU 上复制一些数据,并且需要在每个 GPU 上保留一些内存作为在渲染期间进行计算的缓存器。尽管如此,使用 NVLink 可以让我们渲染比单独使用个别 GPU 更大的场景。
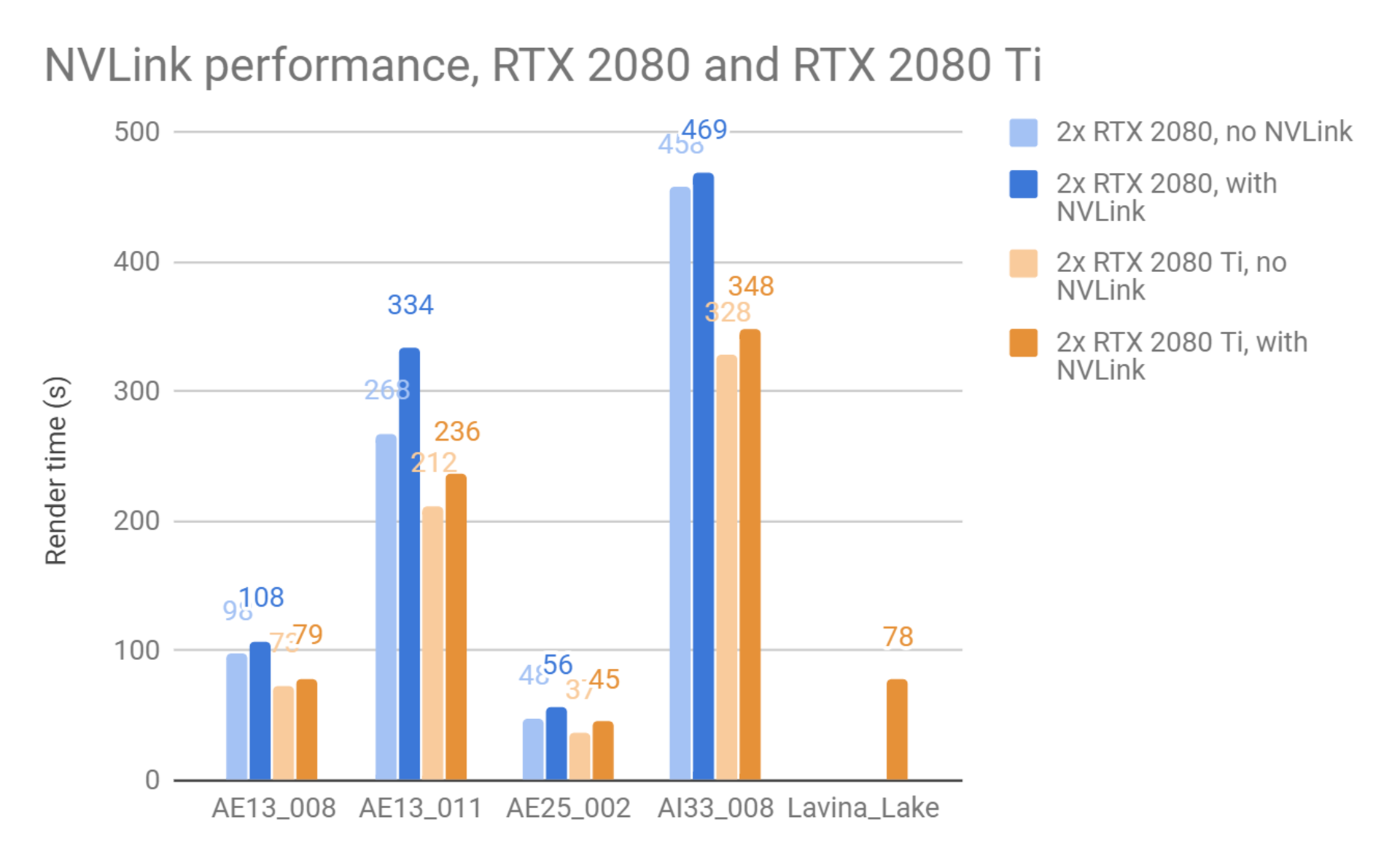
最后一个场景 – 拉维纳之湖(Lake Lavina)只能使用 RTX 2080 Ti 卡在 NVLink 模式下渲染,并且由于GPU内存不足而无法渲染其他测试场景。可以看出,与单独在 GPU 上渲染相比,NVLink 确实导致了一些性能影响,但 NVLink 让我们可以渲染更大的场景。 在许多情况下,速度只是减缓了百分之几。 微调两张卡之间的数据分配方式可以在将来提供更好的性能。
重要提示:看起来 NVIDIA 目前提供的常规 GPU 内存报告 API(在本文截稿日前)在 SLI 模式下无法正常运作。这意味着像 GPUz,MSI Afterburner,nvidia-smi 等程序可能无法显示每个 GPU 的准确内存使用情况。知道有这个问题,我们修改了 V-Ray 帧缓冲区中显示的内存统计信息,以便让您可以跟踪那里的实际 GPU 内存使用情况。预计 NVIDIA 将会修正这些报告问题。

更新版本的 V-Ray GPU 显示的释放的 GPU 内存显示准确的内存数字。

当启用 SLI 时,Nvidia-smi 工具在两张卡上显示出相同内存使用量,但这是不正确的信息。

启用 SLI 时,MSI Afterburner 工具在两张卡上显示出相同内存使用量,但这是不正确的信息。
与其他系统工具相比,V-Ray GPU 在 V-Ray 帧缓冲区中报告的内存使用准确。请注意,V-Ray GPU 报告剩余的可用的 GPU 内存而不是已使用的内存。
结论
当今,新的 RTX 2080 卡提供了比以前使用 V-Ray GPU 的 GTX 1080 卡更好的性能,并且 NVLink 的新功能使得渲染更大的场景成为可能,而性能影响很小。RTX 卡中内置的新 RT 核和 NVLink 技术为未来带来了许多希望,但充分利用 RTX 卡需要对软件进行更多优化和微调,我们希望在未来几个月看到相关优化。

关于作者
Vladimir Koylazov
Vlado 是 Chaos Group 的首席技术官与联合创始人。他是渲染理论的专家,也是 3D 社群的狂热支持者。当不编写代码时,他经常参与论坛讨论并帮助用户解决大家的渲染疑惑。 Vlado 是 V-Ray 背后的重要推手,最近因为促进光线追踪成为电影视觉特效的关键技术而荣获 2017 年奥斯卡科学技术奖。